
For years, American tech titans have insisted that AI will be the determinative advancement of the 21st century, and that we need to give them billions of public funds for the United States to maintain its spot as the world’s foremost technological developer. And many pundits and politicians leapt to champion that position. They all got caught with their pants down.
It turns out that you can develop cutting edge AI with orders of magnitude less money and energy than we’ve been told. The Chinese firm DeepSeek managed to create a program that draws even with or beats just about everyone else for under $6 million dollars. Their reported hardware setup also consumes less than ten percent as much power as Open AI’s hardware (on which ChatGPT-4 was trained), along with using only about eight percent as much memory bandwidth. And DeepSeek did all of this using hardware that was specifically designed to prevent Chinese firms from being able to compete with the American giants.
DeepSeek was able to beat Silicon Valley with a couple of thousand (second-tier) GPUs and $5.5 million. Meta AI publicly was aiming for 600,000 (top tier) GPUs. Sam Altman said he needed $7 trillion to achieve his ideal program. President Trump announced a partnership between SoftBank, OpenAI, Oracle, and MGX called “Stargate.” The program is aiming to spend $500 billion on new AI infrastructure, including $100 billion to begin being disbursed “immediately.”
The name is a bit ironic; the whole Stargate sci-fi franchise is premised on protecting people from being exploited by a ruling class that controls superior technology. Practically every villain in every show and movie is either an extractive overlord who rules with tech superiority and/or a literal hostile AI that turned against its creators. It’s doubly ironic because every entry in the franchise also has a theme of doing more with less. But hey that’s pretty on brand for guys ostensibly inspired by (the famously lefty) Star Trek series who rant and rave against DEI.
On a Spending Spree
According to Intelligent CIO, the United States invested some $200 billion more in AI than China from 2019 to 2023. In fact, U.S. investment almost doubled (188 percent) what the next three leading countries did combined.
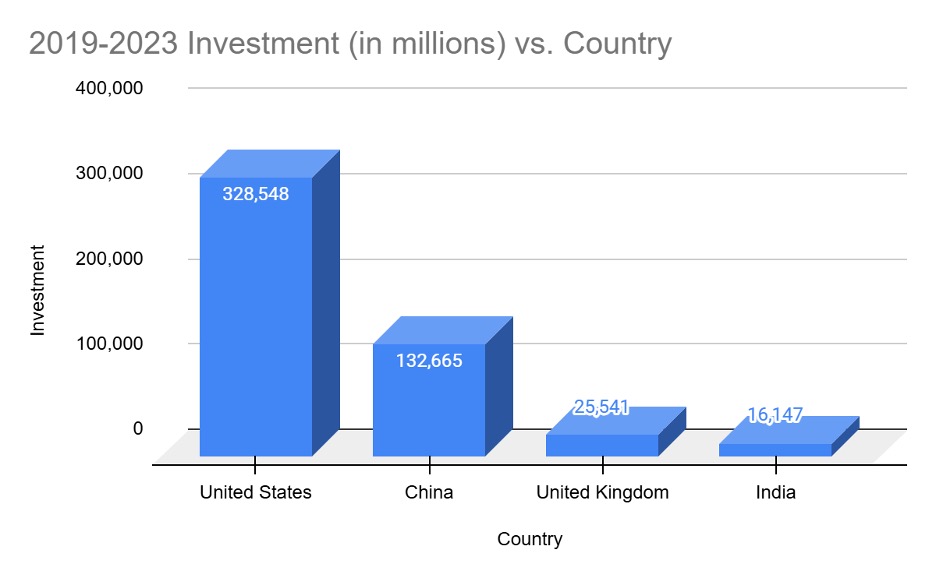
Data from Intelligent CIO, “USA leading the charge on AI investment”
With that kind of funding edge, American AI titans should be leagues ahead, virtually untouchable. So why the panic in January of 2025 when DeepSeek shocked the entire industry, triggering a loss in valuation of over $500 billion in chip-maker Nvidia?
To answer that, we need to understand the political economic view of AI that its proponents have been peddling. Artificial intelligence, the argument goes, is slated to be one of the—perhaps simply the singular—most transformative technology in human history. AI has been promised as the solution to just about every worldly problem, not to mention a fair few metaphysical ones too.
Climate change? AI will be able to solve it. Poverty? AI will usher in an unprecedented wave of productivity and growth that will create more than enough spoils for everyone. The issue of limited resources itself? AI is the key to moving to a post-scarcity economy (like Star Trek, but without those pesky ideals of acceptance and diversity).
This may sound like a ludicrous exaggeration, but a lot of players in Silicon Valley genuinely hold this belief. See, for instance, Mark Andreesen’s “techno-optimist” manifesto, which declares with a totally straight face, that “We believe that there is no material problem—whether created by nature or by technology—that cannot be solved with more technology.”
Or, take a look at former Google CEO Eric Schmidt, who said that we should abandon climate mitigation policies and double down on AI data centers so that we can wait for an algorithmic solution.
One doesn’t need to be a luddite to question this absolute faith in technology. What happens when we’ve let the Earth burn and AI finally gives us the answer? What happens if it’s 42? What if AI simply advises us to cut emissions, like scientists have been urging for decades?
For decades, the cult of a technological cure-all has festered in the frontal lobe of the American political class. Dreams of Mars colonies and interstellar civilizations and a sci-fi future have permeated our public consciousness. And the panacea peddlers have used their capture of our imagination to entrench their self-serving extractive institutions, funneling more and more resources to their gated future. The American AI giants were caught off guard because they fundamentally believed that they were entitled to their hoard without challenge.
The government and public have been led into siphoning enormous amounts of money and attention into an AI arms race that was supposed to be an easy lay-up. Just for a little Chinese company to block the shot in their face.
Even accepting that developing cutting edge AI domestically is important—which is an entirely separate debate—the entire economic paradigm under which the United States has been building is clearly undermined by DeepSeek.
The Political Economy of AI
At the core of the American model of AI development is devotion to the idea of scalability: If you want to train an algorithm to be orders of magnitude more powerful, the trick is to scale up its footprint, usually also by orders of magnitude. That’s why, despite Open AI training ChatGPT-4 on 25,000 last-generation processors, Meta AI felt the need to spend 2024 setting up 600,000 cutting-edge processors. If they want to beat Open AI, they need to outgun them, right?
Well, no. It turns out that this isn’t really the case. Or even if it is partially true, meaningful innovation can occur without this type of scaling.
To preserve Silicon Valley’s dominance, the federal government actually banned the export of current top-of-the-line processors, the NVIDIA H100 GPU. To that end, NVIDIA developed an inferior line of chips specifically to export to Chinese firms without giving them a chance to threaten American AI firms. That chip, the H800, is still a meaningful upgrade over the older A100 (what Open AI used for ChatGPT-4). But even so, the H800 has only 60 percent of the memory bandwidth (how much data can be read/written in a given time interval), half the max power draw, and is capable of only 76 percent of the total operations per second (TOPs). See the chart below for a more detailed breakdown.
| A100 | H100 | H800 | |
| Memory Bandwidth | 1.935 TB/s | 3.35 TB/s | 2 TB/s |
| TOPs | 624 | 3958 | 3026 |
| TFLOPs | 312 | 3958 | 3026 |
| Max Power | 300 W | 700 W | 350 W |
Sources: Stats for the H100 and A100 are from NVIDIA’s website. Stats for the H800 are from Lenovo.
Like TOPs, total floating point operations per second (TFLOPs) is also a measure of how many computations can be performed in a second. The main difference is TOPs represent how many operations with integers can be computed, while TFLOPs represent the number of operations containing decimals (floating points) that can be computed. One of the clearest improvements in the current generation of NVIDIA chips over the last generation is much more efficiency in processing fractional data.
This all gets a bit abstract in a hurry. The next table shows what these chip specifications mean in terms of the total computing power and energy consumption of Meta AI’s target 2024 buildout, Open AI’s training setup for ChatGPT-4, and DeepSeek’s training setup for its V3 model.
| Meta AI | Open AI (ChatGPT 4) | DeepSeek (V3) | |
| Memory Bandwidth | 2,010,000 TB/s | 48,375 TB/s | 4096 TB/s |
| TOPs | 2,374,800,000 | 15,600,000 | 6,197,248 |
| TFLOPs | 2,374,800,000 | 7,800,000 | 6,197,248 |
| Max Power | 420,000,000 W | 7,500,000 W | 716,800 W |
| 24-hr Energy Use | 10,080,000 kWH | 180,000 kWH | 17,203 kWH |
| Equivalent Yearly Homes’ Power (per day) | 93 Homes | 16 Homes | 1 Home |
| 1-yr Energy Use | 3,679,200,000 kWH | 65,700,000 kWH | 6,279,095 kWH |
| Equivalent Yearly Homes’ Power (per year) | 340,950 Homes | 6,088 Homes | 581 Homes |
Sources: Stats for the H100 and A100 are from NVIDIA’s website. Stats for the H800 are from Lenovo. Energy consumption for the average American household is from the Energy Information Administration. The quantity and type of GPUs is based on reporting from Drop Site News.
Meta’s target hardware setup for 2024 uses the same electricity as almost 341,000 average American homes in the same year—as much energy consumption in a day as 93 houses do yearly. Thus, a single company’s AI hardware consumes energy at a rate comparable to a city the size of New Orleans or Orlando. Note that this is just the power drain of the chips themselves, not including anything else in data centers like climate control, lighting, or security systems. Meta’s GPUs alone already consume more than a fourth of the yearly power consumption of a number of larger cities like Nashville, Boston, D.C., and Denver.
Data centers already represent three percent of total US power consumption and are projected to more than double to eight percent by 2030.
The response to DeepSeek in Silicon Valley has been woefully lacking in any form of introspection. Many in the AI industry have been defensive, accusing DeepSeek of illicitly possessing H100 chips and of training on copyrighted data from American firms. If those are the best stories, we should seriously reconsider the political economy of the American AI industry. Let’s assume that DeepSeek actually has triple the reported number of GPUs and all of them are H100s. That would still only be one percent of what Meta AI has. And as far as copyright goes, AI firms have been acting up to now under the assumption their AI models must train on internet data, regardless of copyright. Disrespect for IP protections is literally baked into the business model; it hardly seems notable that DeepSeek would do the same.
Analysts have also contested the $6 million figure, with one research outlet’s report suggesting the real cost for the V3 model could be as high as $1.3 billion. One outlet that covered the report called that figure “staggering.” They should take a look at what U.S. tech firms pay. Again, the Stargate project alone is looking to spend half a trillion dollars. And American cloud computing companies are expected to spend $250 billion on AI hardware in 2025 alone.
That same report also notes that DeepSeek has 50,000 GPUs. Yet the researchers don’t actually dispute that only 2000 were used to train DeepSeek’s model.
Is it Worth it?
As Energy Innovation senior fellow Eric Gimon noted to Bloomberg, this moment resembles a heavy overinvestment in fiber optic cables during the dotcom bubble of the early 2000s. Both instances were rooted in business models that presumed scaling up hardware to be the key component of technological advancement. But engineers figured out how to efficiently transmit more data through the cables, just like DeepSeek figured out how to more efficiently train an AI model.
Given this development, it’s worth reconsidering whether the public ought to continue to subsidize the AI industry, as it clearly poses a massive resource drain and can’t compete with innovators like DeepSeek. Oddly enough, the current policy agenda around AI is massively interventionist, when the same companies reject any sort of regulations in other tech markets.
It sure seems like an excellent moment to question the industry’s calls to relax environmental review to build data centers and the propping up of fossil fuel plants, specifically to power those data centers.